Warum die Zukunft der KI-Risikominimierung nicht auf mechanistischer Programmierung beruht, sondern auf der strukturellen Beherrschung von Sprache.
Jahrzehntelang wurde die Mensch-Computer-Interaktion von Maschinen dominiert, die darauf ausgelegt waren, vorgegebene Regelwerke in einer streng logischen Tradition auszuführen. Folglich stützt sich der aktuelle Ansatz zur „AI Literacy“ (KI-Kompetenz) stark auf MINT-Fächer, Data Science und grundlegende Programmierkenntnisse. Doch dieses mechanistische Paradigma greift zunehmend ins Leere. Wie Nvidia-CEO Jensen Huang feststellte, wird natürliche Sprache auf höchstem Niveau zur dominierenden Programmiersprache der Zukunft. Um KI effektiv nutzen zu können, müssen die Fachkräfte von morgen nicht nur Code beherrschen, sondern vor allem ihre Sprache.
Dieser Wandel erfordert ein radikales Umdenken hinsichtlich der Funktionsweise von Large Language Models (LLMs). Trotz ihres informationstechnischen Ursprungs behandeln moderne Transformer-Modelle Grammatik oder logische Schlussfolgerungen nicht als Fundament. Vielmehr stützen sie sich auf statistische Beziehungen zwischen Wörtern in einem hochdimensionalen Raum, in dem Grammatik lediglich ein emergentes, sekundäres Muster ist. Anstatt Wahrheiten stur zu berechnen, navigiert die KI durch komplexe linguistische Assoziationsketten.
Ein einfaches Beispiel: Wenn Sie eine KI bitten, wie Yoda aus Star Wars zu sprechen, überschreibt dieser Befehl die eigentlich fest verankerten Grammatikregeln des Modells. Die KI ‚vergisst‘ nicht, wie man spricht – sie folgt lediglich der statistischen Anziehungskraft der Figur Yoda. In der durch diesen Input geschaffenen Welt dieses Modells (der residual stream) ist die falsche Grammatik plötzlich das wahrscheinlichste Muster.
KI-Kompetenz lässt sich daher nicht durch eine oberflächliche Sammlung zusammenhangsloser Prompting-Tricks erreichen. Sie erfordert vielmehr eine Verstehen der assoziativen Struktur der Sprache selbst. Um diese Sprachmaschinen sicher zu steuern und einen „semantischen Drift“ (das abgleiten des Modells in unfundierte Generierung) zu verhindern, müssen wir uns von der Perspektive einer rein technischen, logikbasierten Programmierung lösen und einen geisteswissenschaftlichen Ansatz verfolgen. Wir müssen Prompt Engineering nicht als bloßes Erteilen von Instruktionen begreifen, sondern als einen strengen hermeneutischen Eingriff in die assoziative Architektur des Modells.
Keine Sorge: Um ein Auto sicher zu steuern, muss man den Verbrennungsmotor nicht berechnen können. Genauso wenig müssen Ihre Teams für die sichere KI-Nutzung Vektormathematik beherrschen. Das folgende Fundament belegt jedoch die technische und regulatorische Notwendigkeit unseres Ansatzes. Was wir Ihren Teams vermitteln, ist eine methodisch fundierte Rückbesinnung auf eine zutiefst menschliche Fähigkeit: den bewussten und präzisen Umgang mit Sprache. Wir nutzen hierfür die Hermeneutik – eine Disziplin, die Sprache bereits seit über einem Jahrhundert als assoziatives Geflecht begreift und damit heute den Schlüssel zur sicheren Steuerung von Sprachmodellen liefert.
Sprache in Sprachmodellen
In Transformer-Modellen werden Wörter (Tokens) als Vektoren in einem hochdimensionalen Raum repräsentiert. Ihre Bedeutung wird erst durch ihre kontextuellen Beziehungen geformt. Die erste grundlegende Erkenntnis lautet demnach: Die Bedeutung eines Wortes in Large Language Models ist rein kontextuell. Dieser Kontext wird statistisch aus massiven Datensätzen abgeleitet, die menschliche Kultur und Geschichte als mathematische Muster kodieren.
Der Attention-Mechanismus – die zentrale Innovation moderner LLMs – passt diese Beziehungen jedoch dynamisch an, indem er für jedes Token Queries (Suchanfragen), Keys (Schlüssel) und Values (Werte) berechnet. Queries repräsentieren das aktuelle Wort, das nach Kontext sucht; Keys liefern potenzielle Übereinstimmungen; und Values enthalten die Informationen, die für die Generierung des Outputs herangezogen werden. Diese erlernten Projektionen bestimmen, wie Wörter sich in einem bestimmten Satz gegenseitig beeinflussen, und ermöglichen es dem Modell, sich selektiv auf relevante Elemente zu fokussieren.
Betrachten wir ein simples Beispiel: Im Satz „Ich habe den Bären gereizt“ verknüpft der Attention-Mechanismus den „Bären“ mit der Handlung des „Reizens“. Dies verändert seine assoziative Gewichtung. Das Wort „Bär“ ist nun nicht mehr neutral, sondern für das Modell stark mit Aggression oder Provokation verknüpft, weil „gereizt“ in die geometrische Nähe von „Bär“ verschoben wird. Wäre der „Bär“ zuvor als nationales Symbol mit Russland assoziiert gewesen, könnte diese Neugewichtung nun ein aggressives Russland implizieren, statt nur das Land im Allgemeinen. Was hier geschieht, ist eine metaphorische Verschiebung des Wortes in seinem Gebrauch. Seine lexikalischen Verknüpfungen, sein Ort in dem hochdimensionalen Raum werden auf eine Weise verschoben, die strukturell exakt der Funktionsweise einer Metapher entspricht.
Das ist der Moment, in dem die Informatik zur Geisteswissenschaft wird. Die KI ‚rechnet‘ keine Logik, sie navigiert durch Assoziationsketten. Wer die KI steuern will, muss also lernen, diese feinen metaphorischen Verschiebungen zu verstehen. Das ist der Kern einer hermeneutischen Herangehensweise an KI: Sprache nicht als Code zu sehen, sondern als ein dynamisches Beziehungsgeflecht.
Exkurs: Der mathematische Hintergrund
Mathematisch wird dies durch die Berechnung von Attention-Scores erreicht (vgl. Vaswani et al., 2017). Vereinfacht gegeben seien die Input-Embeddings e1 (für Bären) und e4 (für gereizt). Ihr gegenseitiger Einfluss wird wie folgt berechnet:
Diese Attention-Scores werden anschließend mithilfe der Softmax-Funktion normalisiert, um die finalen Gewichtsverteilungen zu ermitteln:
Das finale kontextualisierte Embedding für den „gereizt“ ist somit eine gewichtete Summe seiner eigenen Repräsentation und der von „Bär„, verarbeitet durch eine nicht-lineare Transformation. Infolgedessen ist die mathematische Repräsentation für den gereizten Bären, ein Geflecht aus Beziehungen zu anderen Wörtern, nicht länger nur der „Bär“ oder „gereizt“ in ihrer allgemeinen statistisch erfassten Verwendungsweise. Das Wort „gereizt“ trägt nun eine modifizierte Bedeutung, basierend auf seiner Interaktion mit „Bär“. Was hier stattfindet, ist im klassischen Sinne eine Metapher als logische Operation.
Warum ist dieser mathematische Teil für Sie wichtig? Nicht, weil Sie oder Ihre Teams diese Formeln beherrschen müssen. Sondern weil diese Mathematik der strukturelle Beweis dafür ist, dass Halluzinationen und ‚Semantic Drift‘ keine klassischen Software-Bugs sind, die Ihre IT-Abteilung wegpatchen kann. Wenn Ihre Mitarbeiter die Sprache im Prompt ungenau wählen, zwingt die Mathematik des Modells (die Attention-Scores) die KI physisch dazu, Fakten zu verzerren. Dieser Exkurs beweist: Das Risiko ist strukturell, und die einzige Abwehr ist geschultes sprachliches Bewusstsein beim Anwender.
Entscheidend ist hierbei: Diese Metaphorik ist kein poetisches Beiwerk, sie ist Infrastruktur geworden.
Es handelt sich um die Substitution eines Assoziationsfeldes durch ein anderes, wodurch völlig neue semantische Verknüpfungen in den ursprünglichen Kontext eingeführt werden. Diese strukturelle Verschiebung ist der grundlegende Mechanismus – und das primäre Resultat – beim Prompting eines Transformer-Modells.
Im Praxisalltag läuft dieser Prozess jedoch meist völlig unbewusst ab. Anwender lösen massive semantische Verschiebungen aus, ohne es zu merken, schlicht weil ihnen ein fundiertes, strukturelles Verständnis von Sprache fehlt. Diese unbewusste Nutzung führt zu drei klaren operativen Realitäten:
Die Entstehung von Halluzinationen (Das Risiko): Unbeabsichtigte metaphorische Verschiebungen zwingen das Modell dazu, Verbindungen zu generieren, die zwar statistisch plausibel klingen, denen aber jede sachliche Grundlage fehlt. Dies ist die strukturelle Wurzel des Veracity Bias.
Wissensextraktion (Der Mehrwert): Umgekehrt fungieren gezielte und bewusste metaphorische Verschiebungen als semantische Schlüssel. Durch eine strategische Neugewichtung der Aufmerksamkeit des Modells können Anwender die KI zwingen, auf hochspezifische, sonst unzugängliche Wissensräume zuzugreifen, die mit Alltagssprache schwer erreichbar bleiben.
Die Grenzen der Automatisierung (Der menschliche Faktor): Dieser hermeneutische Prozess entzieht sich weitgehend der Automatisierung. Eine wirklich neuartige oder hochspezifische Verbindung zu erschaffen, erfordert die Konstruktion einer Verknüpfung, die in der aktuellen Datenbasis des Modells noch nicht explizit kartiert ist. Die KI kann sich daher für echte strukturelle Innovationen nicht effektiv selbst prompten.
Hermeneutik im Maschinenraum
Für Entscheidungsträger stellt sich an diesem Punkt eine essenzielle Frage: Sind diese metaphorischen Verschiebungen nur eine philosophische Theorie, oder lassen sie sich in der mathematischen Architektur der Maschine nachweisen?
Um den Beweis zu erbringen, haben wir ein Experiment mit dem Llama 3.1 8B Modell (einem kleinen Open-Weight-Modell mit 32 Layern) durchgeführt. Das Ziel war es, die verborgenen geometrischen Strukturen der KI, den sogenannten „Latent Space“, bei der Verarbeitung von Metaphern sichtbar zu machen.
Wir haben das Modell mit drei unterschiedlichen Texten konfrontiert, um zu testen, ob ein gezielter Prompt tatsächlich eine physische „Brücke“ im Vektorraum der Maschine baut. Bei diesem Prozess lassen wir das Modell den Text nur lesen, d.h. hier ist keine zufällige Generation von Text beinhaltet, sondern nur eine Beschreibung des geometrischen Bereiches den ein Prompt schaffen würde:
Der technische Diskurs: Ein Standardtext über die reine Mechanik von Large Language Models.
Der philosophische Diskurs: Ein Text über Martin Heidegger’s Gedanken zur Technik.
Der hybride Raum: Ein Text, der die Funktionalität von LLMs durch Heideggers Konzept des „Ge-stells“ beschreibt.
Die Baseline: Vergleicht man den reinen LLM-Text mit dem reinen Heidegger-Text, liegt die Überlappung der konzeptionellen Subräume (Subspace Overlap) bei lediglich 0.221. Auf der Ebene einzelner Token-Vergleiche im finalen Layer liegt die durchschnittliche Ähnlichkeit (Cross-Token Mean) sogar bei nur 0.123. Das ist unsere Baseline: Der mathematische Beweis dafür, dass diese beiden metonymischen Felder im Vektorraum der Maschine grundverschieden und extrem weit voneinander entfernt sind.
Die metaphorische Brücke: Sobald wir das Modell mit dem hybriden Text konfrontieren, wird diese Distanz überbrückt. Der hybride Text verschmilzt die Vektoren und teilt sich signifikante konzeptionelle Geometrien mit beiden Ursprungstexten:
- Überlappung Heidegger ↔ Hybrid: 0.480
- Überlappung LLM-Technik ↔ Hybrid: 0.371
Auch auf Token-Ebene springt die Ähnlichkeit des hybriden Textes massiv nach oben: auf 0.238 (zu Heidegger) und 0.234 (zur LLM-Technik). In anderen Worten: Die Token des hybriden Textes sind im Durchschnitt fast doppelt so nah an den beiden reinen Diskursen, wie diese Diskurse zueinander sind.
Aber, vergleichen wir einmal ein einzelnes Wort, dass ein Muster von Tokens ist, und zwar „embedding(s)“. Bei einem solchen Vergleich in dem LLM und dem Hybrid Text wird sofort deutlich was hier passiert:
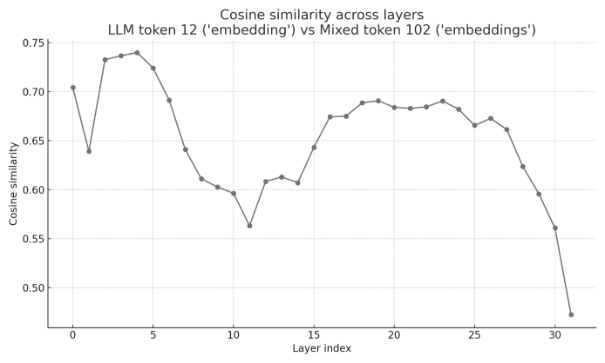
Betrachtet man die Kosinus-Ähnlichkeit der Token-Embeddings über die 32 Verarbeitungsschichten (Layer) des Modells, zeigt sich das Phänomen als Prozess: In den frühen Schichten verarbeitet das Modell vermutlich noch reine Grammatik und Syntax, die Bedeutung, also der Ort im Raum ändert sich kaum. Über die Verarbeitungschichten ändert sich dies und im finalen Layer 31 erzwingt der Diskurs-Kontext eine dramatische Trennung. Die Tokenbedeutung spaltet sich von der statistischen Ausgangssituation in ihre neuen metaphorischen Rollen auf. Die Maschine hat verschiedene spezifische Kontexte aus den Texten errechnet und die semantischen Gewichte im Vektorraum final verschoben.
Was bedeutet dieses Experiment für Ihren Unternehmensalltag? Es zeigt, dass die LLMS auf präzise sprachliche Steuerung reagieren und ‚Brücken‘ zu spezifischem Fachwissen bauen. Ihre Mitarbeiter müssen dafür weder Heidegger lesen noch philosophische Diskurse führen. Sie lernen in unseren Trainings, die eigene Fachsprache zu reflektieren und gezielt für die KI-Nutzung einzusetzen. Es gibt in den Modellen spezifische Wissensnischen, die exakt Ihren Anforderungen entsprechen – und genau diese lernen Ihre Teams sicher anzusteuern und zu beherrschen.
Das Alignment Problem
Aktuelle Erkenntnisse aus der KI-Forschung decken zudem eine strukturelle Schwachstelle auf, die die Sicherheit und verlässliche Steuerung von KI-Modellen ohne Sprachkomptenz erschwert. Ursache dafür ist das Phänomen der Superposition (Elhage et al. 2022, Cunningham et al. 2023).
Um effizient zu arbeiten, pressen neuronale Netze eine riesige Menge an unterschiedlichen Konzepten in einen kleinen Speicherraum. Das bedeutet, dass sich völlig verschiedene – und teils widersprüchliche oder sensible – Themen denselben physischen Platz in der internen Repräsentation von Sprachmustern teilen müssen.
Für die Praxis hat das weitreichende Folgen: Ein einzelner Datenbaustein (ein Token) besitzt isoliert betrachtet keine eindeutige, verlässliche Bedeutung. Welches Konzept das Modell gerade abruft, bleibt unbestimmt, bis das System den kompletten Text-Kontext analysiert hat.
Wenn die KI eine Antwort berechnet, muss sie komplexe, dynamische Filter einsetzen. Sie muss die richtige Bedeutung aus dem Kontext herauslesen und gleichzeitig das „Hintergrundrauschen“ all der anderen, am selben Ort gespeicherten Konzepte aktiv unterdrücken.
Bedeutung ist in Sprachmodellen keine Konstante, sondern ein rein kontextuelles Konstrukt. Das klassische informationstechnische Paradigma – die Von-Neumann-Trennung von Programm und Daten – greift hier schlichtweg nicht mehr. Jeder Lösungsansatz, der weiterhin auf dieser Illusion aufbaut, ist ein technologischer Kategorienfehler, der zu teuren Fehlinvestitionen und ineffizienten Prozessen führt.
Die Herausforderung für Compliance und KI-Sicherheit: Diese Funktionsweise ist ein struktureller Beweis dafür, dass KI-Modelle Bedeutungen nicht an fixe Bedeutung binden oder fest abspeichern, sondern sie bei jeder Anfrage dynamisch aus dem sprachlich gegebenen Kontext neu berechnen. Genau hier entsteht ein fundamentales Alignment-Problem:
Schlägt dieser Filterprozess durch fehlenden Kontext, ungenaue Prompts oder gezielte Manipulationen (Jailbreaks) auch nur minimal fehl, können sich eigentlich getrennte Konzepte plötzlich vermischen. Das System könnte dann harmlose Begriffe mit gefährlichen oder unethischen Konzepten verknüpfen, was es extrem schwer macht, verlässliche Sicherheitsrichtlinien (Guardrails) auf technischer Ebene zu garantieren.
Warum verlässt man sich dann nicht einfach auf vorgefertigte Prompt-Bibliotheken, anstatt in Schulungen zu investieren?
Die Antwort liegt in der Architektur der Modelle: Ein statischer Prompt kann die fehlende informationstechnische Trennung von Daten und Prozess nicht ausgleichen. Jede spezifische Fachinformation und jede sprachliche Nuance, die Ihre Mitarbeiter in das System eingeben, modifiziert den Input dynamisch und verändert damit die Art und Weise, wie die KI ihren Output generiert. Ein Katalog von 10 allgemeinen Standard-Prompts hilft Ihnen in einer dynamischen, hochkomplexen Umgebung überhaupt nicht weiter. Im Gegenteil, er wiegt Anwender in einer trügerischen Sicherheit, während unkontrollierte semantische Verschiebungen provoziert werden.
Fazit: Vom Algorithmus zur semantischen Architektur
Das Zeitalter, in dem KI-Systeme als rein deterministische Rechenmaschinen verstanden wurden, ist vorbei. Wie die Daten aus dem Latent Space beweisen, operieren moderne Large Language Models im Kern als dynamische, assoziative Sprachnetzwerke.
Für Unternehmen und öffentliche Institutionen bedeutet dies einen radikalen Paradigmenwechsel in der Risikobewertung: Die größte Gefahr bei der Implementierung von KI – solide und gut argumentierte Halluzinationen – sind kein Code-Fehler, den eine IT-Abteilung durch ein Software-Update beheben kann.
Es ist ein linguistisches Strukturproblem.
Wer zulässt, dass Teams ohne hermeneutisches Bewusstsein in sensiblen Domänen (wie Recht, Finanzen oder Medizin) mit KI interagieren und arbeiten, provoziert unkontrollierte metaphorische Verschiebungen. Man baut seine KI-gestützten Prozesse auf ein Fundament aus Treibsand. Im Kontext der strengen Transparenz- und Zuverlässigkeitsvorgaben des EU AI Acts verwandeln sich diese „semantischen Drifts“ von einem ärgerlichen IT-Problem in ein massives juristisches und strategisches Haftungsrisiko.
Der Paradigmenwechsel in der KI-Sicherheit
Wahres Risk Mitigation erfordert mehr als Prompt-Engineering-Tutorials und vorgefertigte Prompt Schablonen. Es erfordert die Fähigkeit, die Assoziationen der Maschine zu verstehen und zu kontrollieren.
Genau hier setzt hermeneutic.ai an. Unsere Methodik basiert auf der einzigartigen Verbindung von tiefgreifender KI-Sicherheitsforschung (Mechanistic Interpretability) und Sprachwissenschaft (vergl. Heimann 2026; Heimann and Hübener 2025, 2024, 2023). Doch unser Endprodukt für Sie ist radikal praxisnah. Wir helfen Ihren Mitarbeitern, das Semantic Scaffolding zu errichten und zu erhalten, das Ihre Organisation benötigt. Wir auditieren Ihre Prozesse und übersetzen unsere wissenschaftlichen Erkenntnisse in greifbare, anwendbare Schulungen für Ihre Teams. Ihre Teams lernen, die kritischen semantischen Grenzen der KI zu erkennen und sicher zu navigieren – ohne Vorkenntnisse in Informatik oder Philosophie, sondern schlichtweg mit der Fachsprache und dem Wissen, das sie ohnehin bereits jeden Tag anwenden.
Die sichere Steuerung von Künstlicher Intelligenz erfordert keine besseren Programmierer. Sie erfordert Anwender, die wissen, wie präzise Sprache als Werkzeug funktioniert.
Wir schließen die Lücke zwischen formaler Maschinenberechnung und rechtssicherer menschlicher Anwendung.
Die sichere Steuerung von Künstlicher Intelligenz erfordert keine besseren Programmierer. Sie erfordert eine hermeneutische Beherrschung der Sprache.
Sprechen wir darüber, was das für Ihre Organisation bedeutet.
Cunningham, Hoagy, Aidan Ewart, Logan Riggs, Robert Huben, and Lee Sharkey. 2023. “Sparse Autoencoders Find Highly Interpretable Features in Language Models.” Version 3. Preprint, arXiv. https://doi.org/10.48550/ARXIV.2309.08600.
Elhage, Nelson, Tristan Hume, Catherine Olsson, et al. 2022. “Toy Models of Superposition.” Version 1. Preprint, arXiv. https://doi.org/10.48550/ARXIV.2209.10652.
Heimann, Marc. 2026. “Freudian AI?: Transformer Models as a Proof of Concept for a Central Hypothesis in Freudian Theory.” Lacunae: APPI International Journal for Lacanian Psychoanalysis, no. 29.
Heimann, Marc, and Anne-Friederike Hübener. 2025. “Circling the Void: Using Heidegger and Lacan to Think about Large Language Models: Using Heidegger and Lacan to Think about Large Language Models.” Cognitive Systems Research 91: 101349. https://doi.org/10.1016/j.cogsys.2025.101349.
Heimann, Marc, and Anne-Friederike Hübener. 2024. “The Extimate Core of Understanding: Absolute Metaphors, Psychosis and Large Language Models.” AI & SOCIETY. https://doi.org/10.1007/s00146-024-01971-7.
Heimann, Marc, and Anne-Friederike Hübener. 2023. “Material Calculation and Its Unconscious: Approaching Computerization with Heidegger and Lacan.” Psychoanalysis, Culture & Society. https://doi.org/10.1057/s41282-023-00407-3.
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN,
Kaiser L, Polosukhin I (2017) Attention is all you need. In: 31st
Conference on Neural Information Processing Systems. Advance
online publication. https://doi.org/10.48550/arXiv.1706.03762
Um den mathematischen Brückenschlag im Vektorraum der KI vollständig nachvollziehbar zu machen, finden Sie im Folgenden die drei Originaltexte, die als Input für das Llama 3.1 Modell dienten. Sie veranschaulichen die Ausgangsdistanz der Diskurse und die bewusste hermeneutische Intervention.
Text über Heidegger
Heidegger’s analysis of language begins from the primacy of the pre-predicative articulation of Being. Discourse is not a sequence of propositions but the unfolding of a world already disclosed in Befindlichkeit and Verstehen. The word is not a signifier referring to a prior object; it is the site where the clearing gathers, a locus of worldhood. Hence the seemingly technical neologisms—Ge-stell, Ereignis, Geschick—are not terminological constructions but attempts to reveal the ontological structure that makes predication possible. Every utterance is an articulation of the “as-structure,” the something-as-something through which entities appear at all. To speak is to allow the relational nexus of significance to emerge from concealment and enter into unconcealment. Language, in this sense, is not a human tool but the house in which the truth of Being occurs.
Text über LLMS
Transformer-based language models encode linguistic structure through high-dimensional token embeddings modulated by multi-head self-attention. Each layer computes contextualized representations via learned query–key–value projections that dynamically reweight semantic and syntactic dependencies. During inference, the autoregressive decoder integrates these hidden states to estimate next-token distributions conditioned on the full attention window. The model’s capacity for generalization derives from the statistical geometry of the embedding manifold and the hierarchical abstraction induced by residual connections and layer normalization. Rather than relying on explicit grammatical formalisms, the system models language through distributed associative patterns emergent from large-scale pretraining. Meaning is not symbolically defined but encoded as relative position and activation trajectories in the transformer’s latent space.
Hybridtext
The contemporary large language model can be read as a technically instantiated form of Ge-stell. In the transformer architecture, language is not handled as a series of explicit propositions but as a pre-predicative nexus of token embeddings whose associative weightings already disclose a world close to the they. Multi-head self-attention does not “calculate meaning” in the logical sense; it reconfigures the as-structure, the something-as-something, by dynamically shifting the salience of relations within a high-dimensional embedding space. Each forward pass is the gathering of a world: latent vectors, trained on an historical corpus, are momentarily gathered into a specific articulation that lets entities appear in a determinate way for a given prompt. The model’s latent space is thus a technological clearing in which the Geschick of language—its historically sedimented associations—is rendered operable as a resource. Prompt engineering, in this view, is not mere instruction giving but a hermeneutic intervention into the model’s Ge-stell: a deliberate modulation of attention that steers which regions of the associative manifold are unconcealed and which remain withdrawn in the background of the computation.